
Leveraging the gurobipy-pandas Package to Build a Model
As the INFORMS 2023 Annual Meeting comes to an end this week in Phoenix, I thought I should show
how to use the somewhat new
gurobipy-pandas
package that facilitates building models in
gurobipy using pandas objects and moreover compare the code to the standard
gurobipy-only implementation. I came to learn of this package through a presentation by
Robert Luce
at Gurobi and subsequent conversations with Robert and contributor
Irv Lustig
at Princeton Consultants.
If you’re tired of me posting about the Max-Flow LP model, I have bad news. In this post, we again leverage the Max-Flow optimization model as an example. In this previous post we motivate the following linear programming formulation:
Consider first the following implementation of the Max-Flow LP without pandas:
|
|
Perhaps the trickiest part of the implementation is defining
$\hat{V}_i^+$
and
$\hat{V}\_i^-$
and then using those sets to implement the flow balance constraints via
comprehensions in lines 24-25 above. Not that this is particularly burdensome for this example,
the beauty of gurobipy-pandas (and pandas more generally) is that such comprehensions may be
replaced by invoking Series.groupby as in the script below.
|
|
If every node were to have at least one incoming and outgoing edge, then there would be no need for $V$. Though this occurs in the example we present, it is not generally guaranteed. For the sake of generality, we define the set $V$ so that we may use it for reindexing to ensure the sum of $x_{ij}$ is defined for every node, if even as zero. In this implementation, we enforce $x_{ij} \le c_{ij}$ in the variable declaration unlike how we defined the constraint explicitly in the first implementation.
To avoid having pandas as a dependency for gurobipy, the developers elected to make
gurobipy-pandas a separate optional package. As a consequence, the creation of
pandas-compatible variables and constraints is achieved by invoking functions of the
gurobipy_pandas module rather than by the familiar object methods model.addVar,
model.addConstr, and the like.
In short, the main advantages of using gurobipy-pandas and not just gurobipy are (i) that it
facilitates a data-first (vs. model-first) approach, (ii), that it allows data to be loaded easily
from tabular data files, and (iii) that slicing and groupby/aggregating data in
pandas.Series is computationally very efficient.
Which of these two implementations do you prefer? Do you see yourself using gurobipy-pandas in
the future? (Are you already!?) Let me know in the comments!

You May Also Like
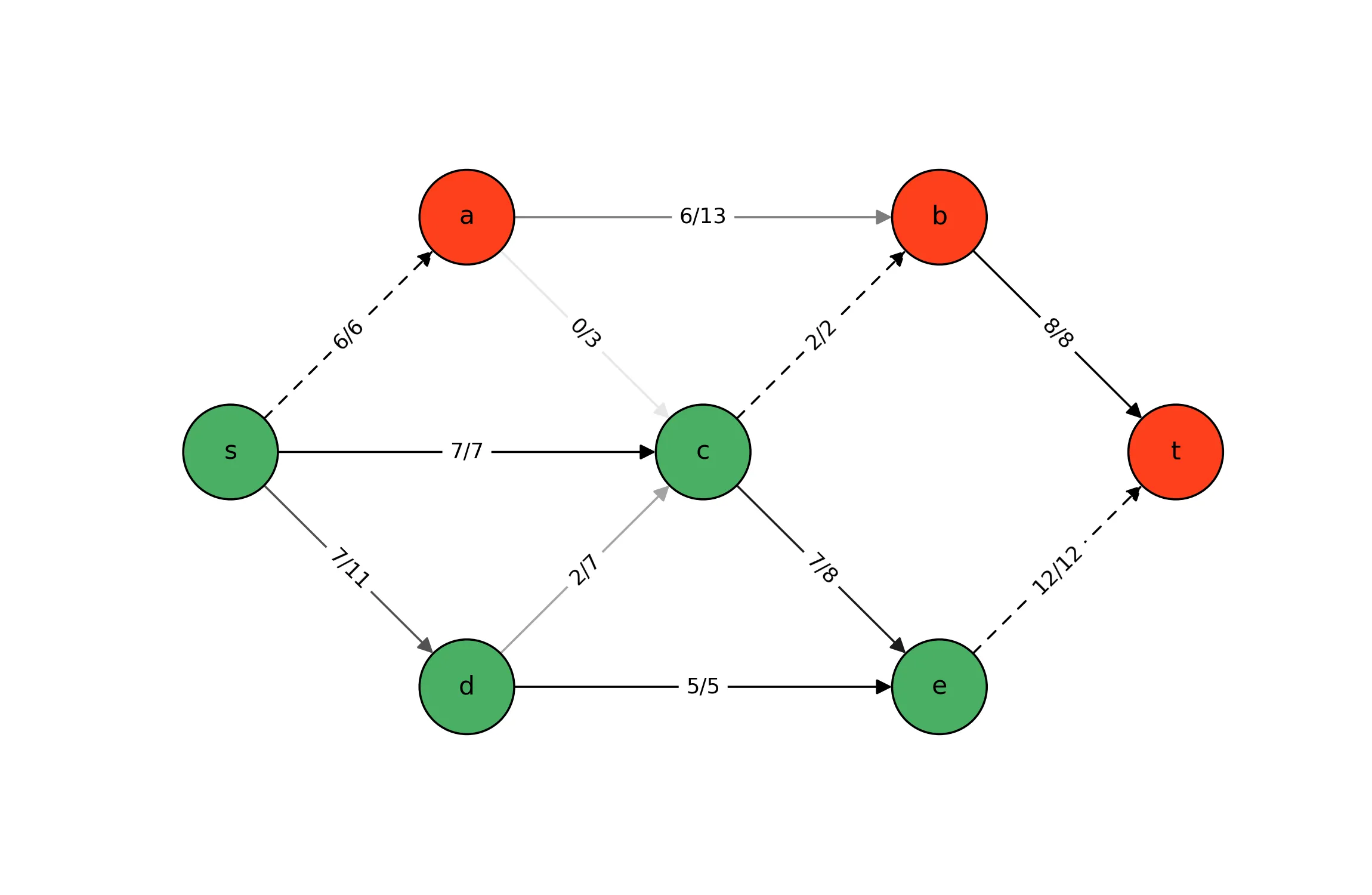
Max-Flow/Min-Cut Duality: Implementation & Visualization
In a previous post, we discussed the strong dual relationship between …

Getting Started with Algebraic Modeling Languages
Algebraic modeling languages like JuMP, gurobipy, Pyomo, CVXPY, and …

Introduction to Pyomo and Gurobipy
This morning, I had the honor of hosting a workshop on behalf of the …